Easy Non-Coding Local LLM
Local LLMs can provide data privacy, security, offline availability, customization, and much more compared to hosted services like ChatGPT/Claude/Bard, etc.


0. Before you continue
This article is very time-sensitive due to the rapid development of AI.
1. Background
- Hugging Face is a machine learning (ML) and data science platform and community that helps users build, deploy and train machine learning models. It provides the infrastructure to demo, run and deploy artificial intelligence (AI) in live applications. Hugging Face
- LM Studio is a user-friendly desktop application designed for experimenting with local and open-source Large Language Models (LLMs). It allows users to discover, download, and run any ggml-compatible model from Hugging Face. LM Studio
2. LLM Download
Note: In this article, operating system is Windows. Also Mac M1/M2 is available
- For demo, I will use the model
Nous Hermes Llama 2 7B - GGUFLink - All Nous-Hermes-Llama-2-7B-GGUF models:
| Name | Quant method | Bits | Size | Max RAM required | Use case |
|---|---|---|---|---|---|
| nous-hermes-llama-2-7b.Q2_K.gguf | Q2_K | 2 | 2.83 GB | 5.33 GB | smallest, significant quality loss - not recommended for most purposes |
| nous-hermes-llama-2-7b.Q3_K_S.gguf | Q3_K_S | 3 | 2.95 GB | 5.45 GB | very small, high quality loss |
| nous-hermes-llama-2-7b.Q3_K_M.gguf | Q3_K_M | 3 | 3.30 GB | 5.80 GB | very small, high quality loss |
| nous-hermes-llama-2-7b.Q3_K_L.gguf | Q3_K_L | 3 | 3.60 GB | 6.10 GB | small, substantial quality loss |
| nous-hermes-llama-2-7b.Q4_0.gguf | Q4_0 | 4 | 3.83 GB | 6.33 GB | legacy; small, very high quality loss - prefer using Q3_K_M |
| nous-hermes-llama-2-7b.Q4_K_S.gguf | Q4_K_S | 4 | 3.86 GB | 6.36 GB | small, greater quality loss |
| nous-hermes-llama-2-7b.Q4_K_M.gguf | Q4_K_M | 4 | 4.08 GB | 6.58 GB | medium, balanced quality - recommended |
| nous-hermes-llama-2-7b.Q5_0.gguf | Q5_0 | 5 | 4.65 GB | 7.15 GB | legacy; medium, balanced quality - prefer using Q4_K_M |
| nous-hermes-llama-2-7b.Q5_K_S.gguf | Q5_K_S | 5 | 4.65 GB | 7.15 GB | large, low quality loss - recommended |
| nous-hermes-llama-2-7b.Q5_K_M.gguf | Q5_K_M | 5 | 4.78 GB | 7.28 GB | large, very low quality loss - recommended |
| nous-hermes-llama-2-7b.Q6_K.gguf | Q6_K | 6 | 5.53 GB | 8.03 GB | very large, extremely low quality loss |
| nous-hermes-llama-2-7b.Q8_0.gguf | Q8_0 | 8 | 7.16 GB | 9.66 GB | very large, extremely low quality loss - not recommended |
- For demo purpose, I’m using the
nous-hermes-llama-2-7b.Q4_K_M.ggufmodel. - Put the file under
/your_path/author_name/repo_name/
3. Essentials
- As of 20231001, GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp. GGUF offers numerous advantages over GGML, such as better tokenisation, and support for special tokens. It is also supports metadata, and is designed to be extensible.
- Download Visual Studio latest version and install
Desktop development with C++,MSVC vxxx -VS 2022 C++ x64/x86 build tools,C++ Clang Compiler for Windows,C++ CMake tools for Windows. - Run
pip install llama-cpp-python
4. LM Studio Download
- Go to official website and download the latest version of LM Studio.
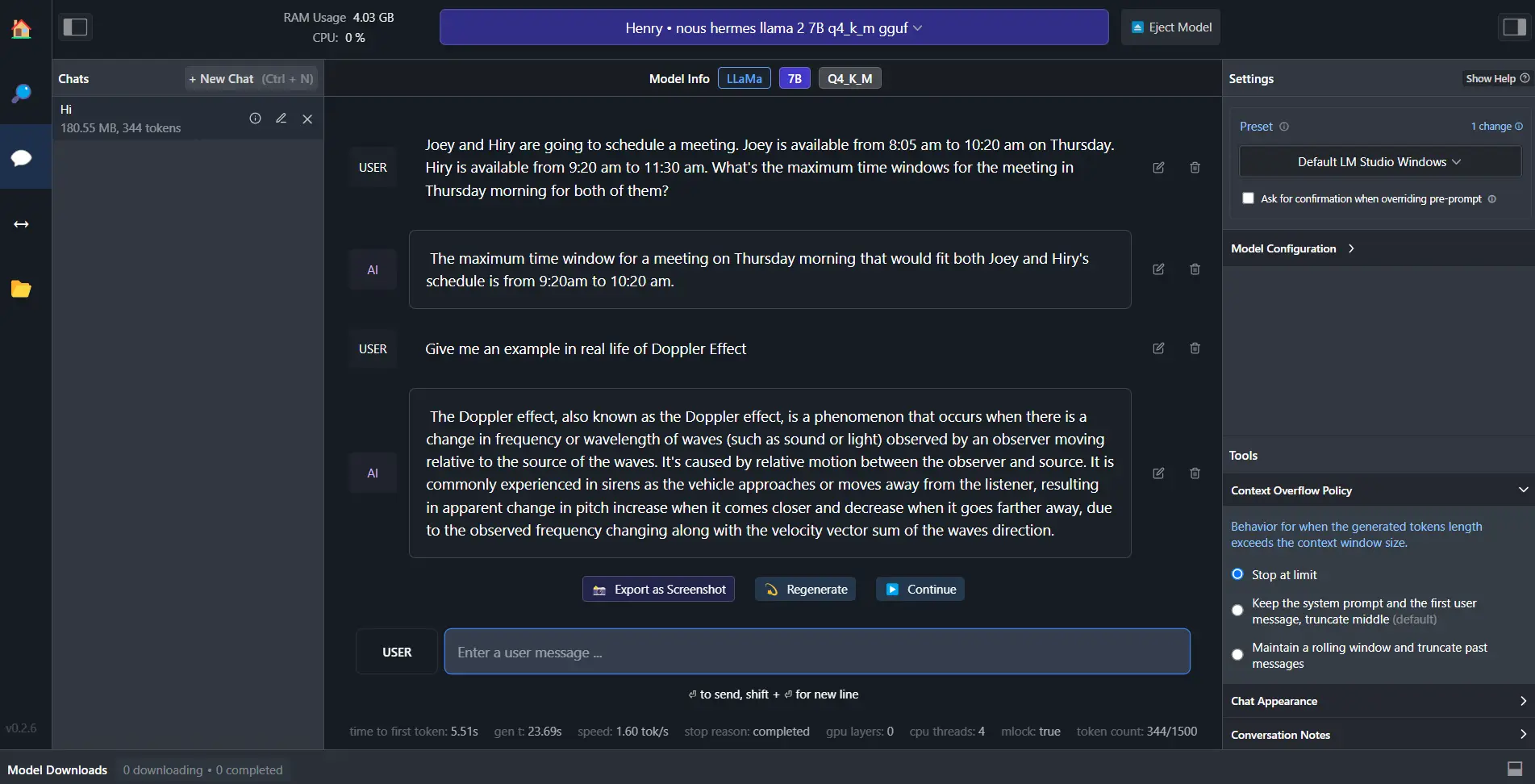
- Load your model and enjoy.
Copyright statement: Unless otherwise stated, all articles on this blog adopt the CC BY-NC-SA 4.0 license agreement. For non-commercial reprints and citations, please indicate the author: Henry, and original article URL. For commercial reprints, please contact the author for authorization.