How to Train Your Own Voice Model with Tortoise-TTS
a very expressive TTS system with impressive voice cloning capabilities


1. Background
Tortoise is a text-to-speech program built with the following priorities:
- Strong multi-voice capabilities.
- Highly realistic prosody and intonation.
2. Pre-requisites
To train your own voice model using Tortoise-TTS, make sure you have:
- GPU runtime
- Basic knowledge of Python
- Enough high quality voice samples
3. (Optional) Use your own voice as voice model
If you’d like to use your own voice as voice model, personally I recommend you to record them based on Harvard Sentences
The Harvard sentences, sometimes called Harvard lines, is a collection of 720 sample phrases, divided into lists of 10, used for standardized testing of Voice over IP, cellular, and other telephone systems. They are phonetically balanced sentences that use specific phonemes at the same frequency they appear in English. (example below)
| List 1 | |
|---|---|
| 1 | The birch canoe slid on the smooth planks. |
| 2 | Glue the sheet to the dark blue background. |
| 3 | It's easy to tell the depth of a well. |
| 4 | These days a chicken leg is a rare dish. |
| 5 | Rice is often served in round bowls. |
| 6 | The juice of lemons makes fine punch. |
| 7 | The box was thrown beside the parked truck. |
| 8 | The hogs were fed chopped corn and garbage. |
| 9 | Four hours of steady work faced us. |
| 10 | A large size in stockings is hard to sell. |
You can download Audacity
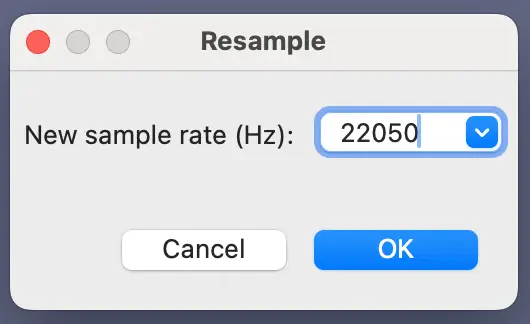
Record at least 3 voice samples (preferably over 10) in .wav format. The default sample rate may be 44100 Hz. You better re-sample it to 22050 Hz.
4. Main python
I’m using Google Colab for demo purposes.
- Pre-steps
# the scipy version packaged with colab is not tolerant of misformated WAV files.
# install the latest version.
pip3 install -U scipy
git clone https://github.com/henrywithu/tortoise-tts.git
cd tortoise-tts
pip3 install -r requirements.txt
pip3 install transformers==4.19.0 einops==0.5.0 rotary_embedding_torch==0.1.5 unidecode==1.3.5
python3 setup.py install
- Import libraries
# Imports used through the rest of the notebook.
import torch
import torchaudio
import torch.nn as nn
import torch.nn.functional as F
import IPython
from tortoise.api import TextToSpeech
from tortoise.utils.audio import load_audio, load_voice, load_voices
# This will download all the models used by Tortoise from the HuggingFace hub.
tts = TextToSpeech()
The output can be:
Downloading: 100%
2.06k/2.06k [00:00<00:00, 143kB/s]
Downloading: 100%
1.18G/1.18G [00:19<00:00, 57.7MB/s]
Downloading: 100%
159/159 [00:00<00:00, 12.0kB/s]
Downloading: 100%
1.57k/1.57k [00:00<00:00, 23.5kB/s]
Downloading: 100%
181/181 [00:00<00:00, 12.2kB/s]
Downloading: 100%
85.0/85.0 [00:00<00:00, 6.30kB/s]
Downloading autoregressive.pth from https://huggingface.co/jbetker/tortoise-tts-v2/resolve/main/.models/autoregressive.pth...
Done.
Downloading classifier.pth from https://huggingface.co/jbetker/tortoise-tts-v2/resolve/main/.models/classifier.pth...
Done.
Downloading clvp2.pth from https://huggingface.co/jbetker/tortoise-tts-v2/resolve/main/.models/clvp2.pth...
Done.
Downloading cvvp.pth from https://huggingface.co/jbetker/tortoise-tts-v2/resolve/main/.models/cvvp.pth...
Done.
Downloading diffusion_decoder.pth from https://huggingface.co/jbetker/tortoise-tts-v2/resolve/main/.models/diffusion_decoder.pth...
Done.
Downloading vocoder.pth from https://huggingface.co/jbetker/tortoise-tts-v2/resolve/main/.models/vocoder.pth...
Done.
Downloading rlg_auto.pth from https://huggingface.co/jbetker/tortoise-tts-v2/resolve/main/.models/rlg_auto.pth...
Done.
Downloading rlg_diffuser.pth from https://huggingface.co/jbetker/tortoise-tts-v2/resolve/main/.models/rlg_diffuser.pth...
Done.
- Input the message you want to be converted to voice, also determine the quality (the higher the slower)
# This is the text that will be spoken.
text = "Poggers, bro! The weather is good today. What is your plan for the weekend? Shall we go to see a movie?"
# Pick a "preset mode" to determine quality. Options: {"ultra_fast", "fast" (default), "standard", "high_quality"}. See docs in api.py
preset = "fast"
- Upload your voice samples (change your name). You can multi-select your wav files.
# Optionally, upload use your own voice by running the next two cells. I recommend
# you upload at least 2 audio clips. They must be a WAV file, 6-10 seconds long.
CUSTOM_VOICE_NAME = "henry"
import os
from google.colab import files
custom_voice_folder = f"tortoise/voices/{CUSTOM_VOICE_NAME}"
os.makedirs(custom_voice_folder)
for i, file_data in enumerate(files.upload().values()):
with open(os.path.join(custom_voice_folder, f'{i}.wav'), 'wb') as f:
f.write(file_data)
The output can be:
10 files
1.wav(audio/wav) - 1943360 bytes, last modified: 10/6/2023 - 100% done
2.wav(audio/wav) - 1948336 bytes, last modified: 10/6/2023 - 100% done
3.wav(audio/wav) - 1838908 bytes, last modified: 10/6/2023 - 100% done
4.wav(audio/wav) - 1938388 bytes, last modified: 10/6/2023 - 100% done
5.wav(audio/wav) - 1953308 bytes, last modified: 10/6/2023 - 100% done
6.wav(audio/wav) - 1943360 bytes, last modified: 10/6/2023 - 100% done
7.wav(audio/wav) - 1823984 bytes, last modified: 10/6/2023 - 100% done
8.wav(audio/wav) - 1928440 bytes, last modified: 10/6/2023 - 100% done
9.wav(audio/wav) - 1843880 bytes, last modified: 10/6/2023 - 100% done
10.wav(audio/wav) - 1828960 bytes, last modified: 10/6/2023 - 100% done
Saving 1.wav to 1.wav
Saving 2.wav to 2.wav
Saving 3.wav to 3.wav
Saving 4.wav to 4.wav
Saving 5.wav to 5.wav
Saving 6.wav to 6.wav
Saving 7.wav to 7.wav
Saving 8.wav to 8.wav
Saving 9.wav to 9.wav
Saving 10.wav to 10.wav
- Generate speech. The duration of this step varies, highly depending on your quality, number of samples, length of your message, etc. Make sure you have enough RAM & VRAM.
# Generate speech with the custotm voice.
voice_samples, conditioning_latents = load_voice(CUSTOM_VOICE_NAME)
gen = tts.tts_with_preset(text, voice_samples=voice_samples, conditioning_latents=conditioning_latents,
preset=preset)
torchaudio.save(f'generated-{CUSTOM_VOICE_NAME}.wav', gen.squeeze(0).cpu(), 24000)
IPython.display.Audio(f'generated-{CUSTOM_VOICE_NAME}.wav')
The output can be:
Generating autoregressive samples..
100%|██████████| 6/6 [00:45<00:00, 7.52s/it]
Computing best candidates using CLVP and CVVP
0%| | 0/6 [00:00<?, ?it/s]/usr/local/lib/python3.10/dist-packages/torch/utils/checkpoint.py:31: UserWarning: None of the inputs have requires_grad=True. Gradients will be None
warnings.warn("None of the inputs have requires_grad=True. Gradients will be None")
100%|██████████| 6/6 [00:18<00:00, 3.14s/it]
Transforming autoregressive outputs into audio..
100%|██████████| 80/80 [00:34<00:00, 2.35it/s]
5. Demo result
Text:
Poggers, bro! The weather is good today. What is your plan for the weekend? Shall we go to see a movie?
Copyright statement: Unless otherwise stated, all articles on this blog adopt the CC BY-NC-SA 4.0 license agreement. For non-commercial reprints and citations, please indicate the author: Henry, and original article URL. For commercial reprints, please contact the author for authorization.