OpenGPTs: An Open-Source Alternative to OpenAI's GPTs and Assistants API
Powerful, flexible, and easy to use.


OpenGPTs
OpenGPTs is an open source effort to create a similar experience to OpenAI's GPTs and Assistants API. It is powered by LangGraph - a framework for creating agent runtimes. It also builds upon LangChain, LangServe and LangSmith. OpenGPTs gives you more control, allowing you to configure:
- The LLM you use (choose between the 60+ that LangChain offers)
- The prompts you use (use LangSmith to debug those)
- The tools you give it (choose from LangChain's 100+ tools, or easily write your own)
- The vector database you use (choose from LangChain's 60+ vector database integrations)
- The retrieval algorithm you use
- The chat history database you use
Most importantly, it gives you full control over the cognitive architecture of your application. Currently, there are three different architectures implemented:
- Assistant
- RAG
- Chatbot

 langchain-ai
langchain-aiDifferent Architectures
1. Assistants
Assistants can be equipped with an arbitrary amount of tools and use an LLM to decide when to use them. This makes them the most flexible choice, but they work well with fewer models and can be less reliable.
When creating an assistant, you specify a few things.
First, you choose the language model to use. Only a few language models can be used reliably well: GPT-3.5, GPT-4, Claude, and Gemini.
Second, you choose the tools to use. These can be predefined tools OR a retriever constructed from uploaded files. You can choose however many you want.
The cognitive architecture can then be thought of as a loop. First, the LLM is called to determine what (if any) actions to take. If it decides to take actions, then those actions are executed and it loops back. If no actions are decided to take, then the response of the LLM is the final response, and it finishes the loop.
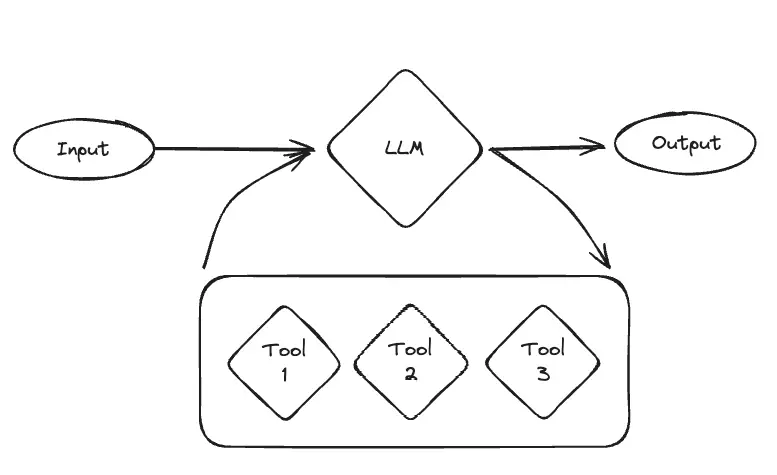
This can be a really powerful and flexible architecture. This is probably closest to how us humans operate. However, these also can not be super reliable, and generally only work with the more performant models (and even then they can mess up). Therefore, we introduced a few simpler architectures.
2. RAGBot
One of the big use cases of the GPT store is uploading files and giving the bot knowledge of those files. What would it mean to make an architecture more focused on that use case?
We added RAGBot - a retrieval-focused GPT with a straightforward architecture. First, a set of documents are retrieved. Then, those documents are passed in the system message to a separate call to the language model so it can respond.
Compared to assistants, it is more structured (but less powerful). It ALWAYS looks up something - which is good if you know you want to look things up, but potentially wasteful if the user is just trying to have a normal conversation. Also importantly, this only looks up things once - so if it doesn’t find the right results then it will yield a bad result (compared to an assistant, which could decide to look things up again).
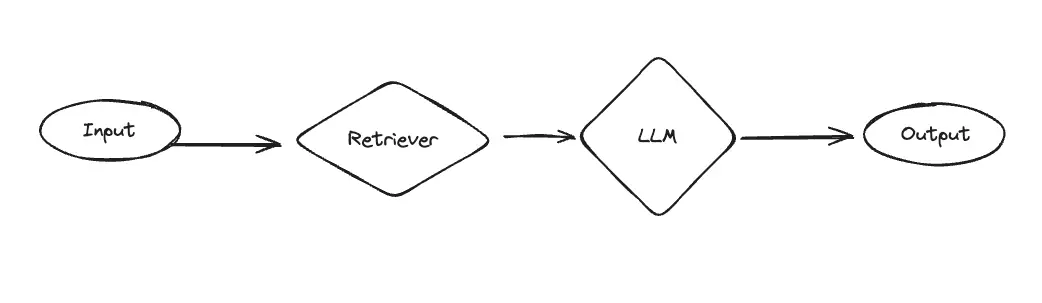
Despite this being a more simple architecture, it is good for a few reasons. First, because it is simpler it can work pretty well with a wider variety of models (including lots of open source models). Second, if you have a use case where you don’t NEED the flexibility of an assistant (eg you know users will be looking up information every time) then it can be more focused. And third, compared to the final architecture below it can use external knowledge.
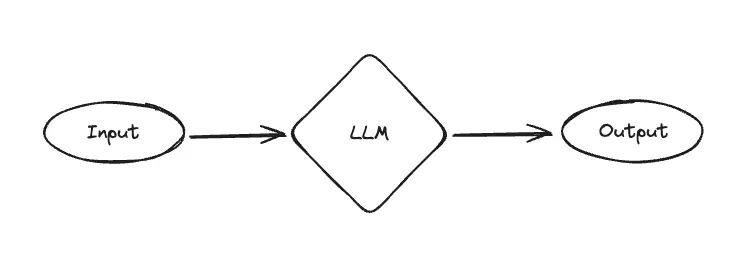
3. ChatBot
The final architecture is dead simple - just a call to a language model, parameterized by a system message. This allows the GPT to take on different personas and characters. This is clearly far less powerful than Assistants or RAGBots (which have access to external sources of data/computation) - but it’s still valuable! A lot of popular GPTs are just system messages at the end of the day, and CharacterAI is crushing it despite largely just being system messages as well.
Docker Deployment
- Clone the Repository
git clone https://github.com/langchain-ai/opengpts.git
cd opengpts
- Edit .env
Adjust the .env file as required for specific environment configurations.
cp .env.example .env
nano .env
OPENAI_API_KEY=placeholder
ANTHROPIC_API_KEY=placeholder
YDC_API_KEY=placeholder
TAVILY_API_KEY=placeholder
AZURE_OPENAI_DEPLOYMENT_NAME=placeholder
AZURE_OPENAI_API_KEY=placeholder
AZURE_OPENAI_API_BASE=placeholder
AZURE_OPENAI_API_VERSION=placeholder
ROBOCORP_ACTION_SERVER_URL=https://dummy-action-server.robocorp.link
ROBOCORP_ACTION_SERVER_KEY=dummy-api-key
- Run with Docker Compose
This command builds the Docker images for the frontend and backend from their respective Dockerfiles and starts all necessary services, including Redis.
Check compose file carefully before you run it:
version: "3"
services:
redis:
container_name: opengpts-redis
image: redis/redis-stack-server:latest
ports:
- "6379:6379"
volumes:
- ./redis-volume:/data
backend:
container_name: opengpts-backend
build:
context: backend
ports:
- "8100:8000" # Backend is accessible on localhost:8100
depends_on:
- redis
env_file:
- .env
volumes:
- ./backend:/backend
environment:
REDIS_URL: "redis://opengpts-redis:6379"
command:
- --reload
frontend:
container_name: opengpts-frontend
build:
context: frontend
volumes:
- ./frontend/src:/frontend/src
ports:
- "5173:5173" # Frontend is accessible on localhost:5173
environment:
VITE_BACKEND_URL: "http://opengpts-backend:8000"
- Bring up the container
docker compose up
- Access the Application
With the services running, access the frontend athttp://localhost:5173, substituting5173with the designated port number. - (optional) Rebuilding After Changes
If you make changes to either the frontend or backend, rebuild the Docker images to reflect these changes.
docker compose up --build
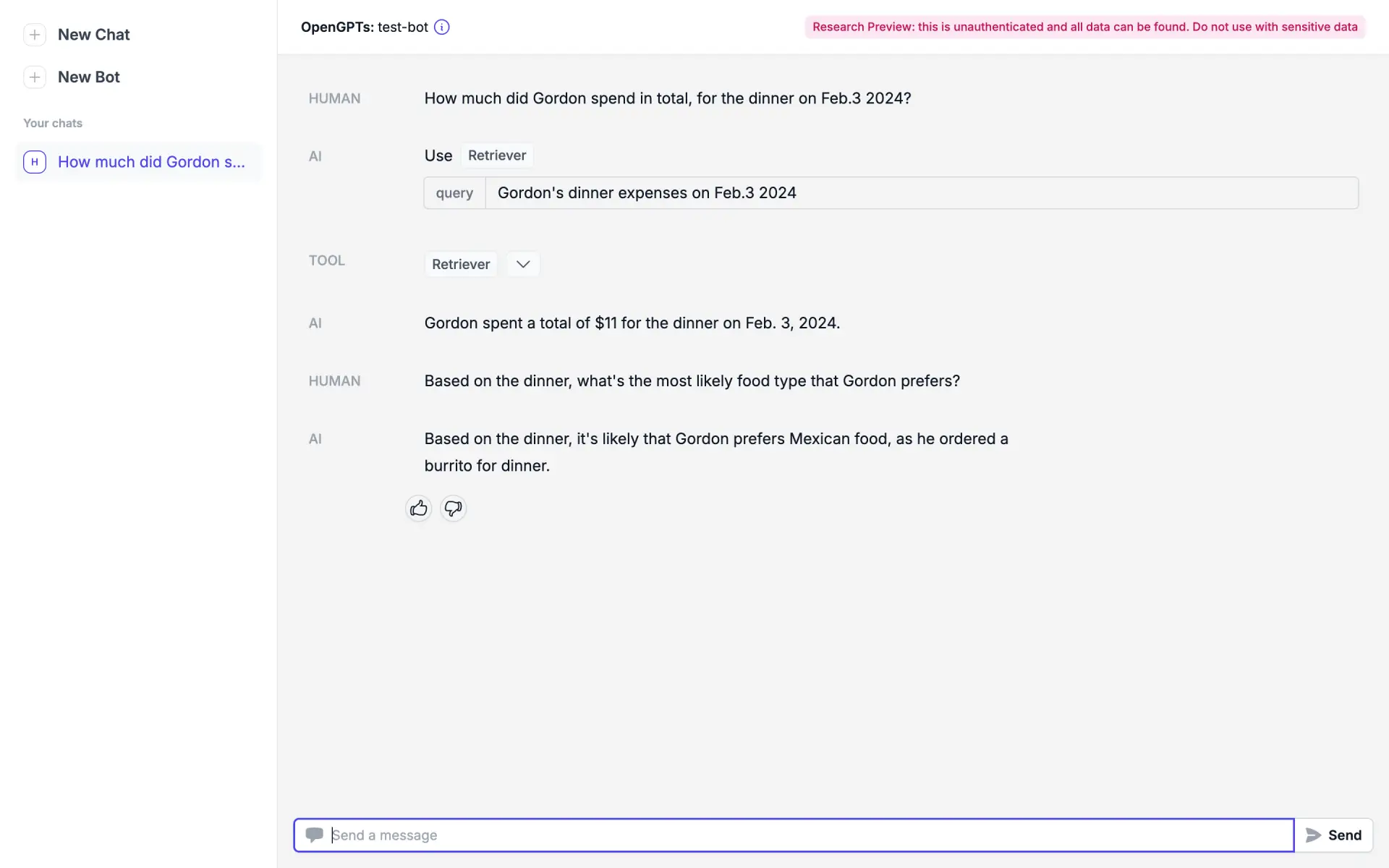
Demo
I’m using assistant as demo.
Note: As of 20240203, this project is highly experimental and with bunch of features to be added & updated. It's recommended that you deploy it locally first.

Appendix
Time-sensitive As of 20240203:
Assume (each call):
| Tokens | Words equiv. | |
|---|---|---|
| Input | 100 | 75 |
| Output | 500 | 375 |
Price Comparison:
| Provider | Model | Context | Input/1k Tokens | Output/1k Tokens | Per Call | 100 Calls |
|---|---|---|---|---|---|---|
| OpenAI | GPT-3.5 Turbo | 16K | $0.001 | $0.002 | $0.0011 | $0.11 |
| OpenAI | GPT-4 Turbo | 128K | $0.01 | $0.03 | $0.016 | $1.60 |
| OpenAI | GPT-4 | 8K | $0.03 | $0.06 | $0.033 | $3.30 |
| Gemini Pro | 32K | $0.001 | $0.002 | $0.0011 | $0.11 | |
| Anthropic | Claude 2.1 | 200K | $0.008 | $0.024 | $0.0128 | $1.28 |
Copyright statement: Unless otherwise stated, all articles on this blog adopt the CC BY-NC-SA 4.0 license agreement. For non-commercial reprints and citations, please indicate the author: Henry, and original article URL. For commercial reprints, please contact the author for authorization.